智能家居领域作为与普通民主生活关系最密切的领域,如何实现智能家居的友好、自然交互是当前重点研究任务。知识图谱以结构化形式表述现实世界中各知识之间的关系,能更加准确地描述实体之间的关系以及实体的属性和属性值。本文以智能家居为例,提出一种基于智能家居领域的问答系统知识图谱构建方法,并分别从实体抽取、关系抽取两方面进行阐述。
3.1 知识图谱构建概述
本文在智能家居领域构建智能家居专用知识图谱,将知识图谱与问答系统相结合,提出针对家居设备的控制新方式,提升家居控制系统人机交互的能力。
3.1.1 知识图谱
知识图谱问答系统是基于图结构问答系统[44]。知识图谱中结点表示实体或实体的属性值,<实体,关系,实体>或<实体,属性,属性值>的三元组形式存放结构化知识。本文针对智能家居领域构建智能家居知识图谱,图谱构建流程如图3-1所示。
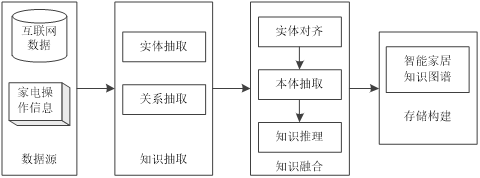
图3-1 智能家居知识图谱构建流程
Fig.3-1 Smart home knowledge map construction process
3.1.2 知识图谱构成
智能家居领域的问答知识图谱包括:数据来源、知识抽取、知识融合、知识存储四部分[25]。
1)数据源。智能家居领域知识图谱的知识来源主要包括两部分,互联网百科数据、智能家电操作数据。
2)知识抽取。知识抽取是指将汇总后的数据,从智能家居数据和互联网百科数据中抽取构建智能家居知识图谱所需的结构化信息。实体抽取、关系抽取是知识抽取的主要内容。
3)知识融合。智能家居知识图谱的知识融合是指将知识抽取后得到的三元组知识信息依次经过实体对齐、本体抽取、知识推理完成新、旧知识的融合。
4)知识存储。知识图谱作为有向图结构的知识库,采用图数据库进行存储,既能有效提高检索效率,又能实现结果可视化。
3.2 智能家居问答系统实体抽取
本节通过对于智能家居领域的非结构化数据进行实体抽取,将问题中出现的人、家居、操作等实体抽取出来,完成智能家居知识三元组的实体构建,得到用户对智能家居的操作知识诉求。通过对实体抽取方法的对比分析,针对智能家居问答系统具体应用情况,提出基于规则和条件随机场相结合的实体抽取方法,并通过对不同抽取方法的对比,分析算法有效性。
3.2.1 实体抽取方法
实体抽取,即命名实体识别(Named entity recognition,NER)[37]是在实体识别的基础上,确定文本中实体类别,如(李明)人名、(北京)地名、(3月12日)时间等,最终以结构化的形式进行存储和应用。根据MUC命名实体规范建立如表所示的7大类实体类型[45]分别是:人物、时间、数字、描述、其他、地点、机构。
表3-1 MUC命名实体规范
Table3-1 MUC named entity specification
类别 |
英文缩写 |
英文全称 |
示例 |
人物 |
PER |
Person |
李明 |
时间 |
TIME |
Time |
2019年 |
数字 |
NUM |
Number |
244553 |
描述 |
DES |
Description |
李明是运动员 |
地点 |
LOC |
Location |
北京 |
机构 |
ORG |
Organization |
北京大学 |
其他 |
NONE |
None |
1+2=3 |
目前,常用的实体抽取方法有Hidden Markov Model,HMM、最大熵模型、CRF模型和基于规则的实体抽取等。
(1)隐马尔可夫模型
利用HMM模型进行实体抽取是将观察值为文体,状态值为实体。由于在实际应用中,HMM模型计算所需的联合概率往往很难计算得出,并且HMM模型对多种特征联合效果较差,因此HMM模型已逐渐被条件模型取代。
(2)最大熵模型
最大熵模型是采用信息熵最大建模。在实体抽取中,通过输入抽取序列及对应标注类别,构建最大熵模型完成实体的抽取。最大熵模型在一定程度上提高了对出现概率的最大化标记;针对不同的问题可以选取不同的特征构建不同的模型;同时最大熵模型可自动调节拟合度和适应度。
(3)条件随机场模型
CRF模型是对最大熵-HMM模型优化的新模型,它具有最大熵模型的优点,又可避免最大偏置问题。因此本文采用CRF进行实体抽取。
(4)基于规则的实体抽取
实体抽取规则的制订需要依据实体本身所在的文本环境,通过定义实体本身、实体边界和同义多实体等方式,使规则充分覆盖文本中包含的实体。基于规则的实体抽取方法在小语料中,具有抽取效果好、速度快的特点。但是,抽取规则需要人工定义和总结,耗时且费力,并且抽取规则往往针对某一或某种特殊语料,可移植性差。
3.2.2 基于规则和条件随机场实体抽取方法
针对智能家居问答系统知识图谱构建思路,提出基于规则和条件随机场相结合的实体抽取方法。对不同来源数据分别采用基于规则的实体抽取和条件随机场实体抽取,最后将抽取结果进行整合,共同构成智能家居知识图谱实体集。
(1)基于规则的实体抽取
考虑到智能家居问答系统数据的多元性,而智能家居操作文本数据和普通问答知识数据有明显的词汇、语义区分,且家居操作文本数据往往具有明显的触发词汇,因此,本文对家居操作文本数据采用基于规则是实体抽取方法。
根据智能家居文本应用场景,设计电器名称、常用动作、时间词、数词等四类触发词。部分常用触发词表如表3-1所示。
表3-1 部分常用触发词
Table3-1 Some commonly used trigger words
电器触发词 |
动作触发词 |
时间触发词 |
数量触发词 |
电视 |
打开 |
早上 |
10点 |
空调 |
关闭 |
中午 |
一档 |
台灯 |
提高 |
晚上 |
上一级 |
音箱 |
降低 |
上午 |
13 |
冰箱 |
加速 |
下午 |
26℃ |
基于规则的实体抽取算法实现思路如下:
1) 首先对智能家居文本进行分词处理、获取单个词语及对应词性;
2) 将单一词语根据常用触发词表不同类别进行过滤,并获取触发词类别,得到待确认实体;
3) 将待确认实体、词性、触发词类别同时筛选匹配,得到最终确认实体
(2)条件随机场实体抽取
针对不规则的互联网文本数据,原有基于触发词的规则抽取已不能满足应用需要。通过对机器学习方法对比分析,本文采用CRF算法进行实体抽取。首先,对智能家居知识文本进行词性标注(Part-Of-Speech tagging,POS tagging)。根据标注结果训练CRF模型[42],完成对命名实体的抽取。
基于CRF的实体抽取算法实现思路如下:
1)文本表示
首先,智能家居实体识别模型通过字符嵌入层将文本符号转换为数字向量进行表示[23]。本文中采用分布式表示方法对字符进行表示。由于命名实体识别模型的标签种类有限,因此CRF标签嵌入层采用One-Hot方法进行表示[47]。
字符分布式表示法是基于CBOW构建Word2Vec模型。其计算公式为:
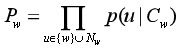 (3-1)
(3-1)
其中,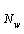 为负样本集,
为负样本集,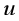 为文本中的任一词语。
为文本中的任一词语。
2)构建CRF实体识别数学模型
给定文本X,得到输出文本Y的条件概率P(Y|X)。
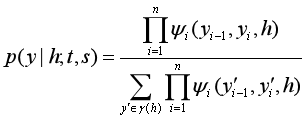 (3-2)
(3-2)
其中,学习条件概率为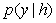 ,
,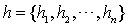 ,为文本序列的分布式表示,
,为文本序列的分布式表示,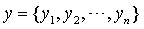 为标签序列。
为标签序列。
对公式3.2进行推理得:
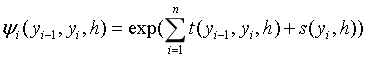 (3-3)
(3-3)
其中,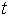 为输入序列
为输入序列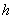 标注序列从
标注序列从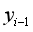 到
到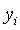 的转移概率。
的转移概率。
采用最大似然估计训练CRF层,对数似然函数如公式3.4所示。
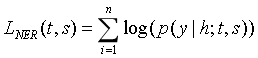 (3-4)
(3-4)
在模型解码时采用维特比算法,确定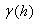 中条件概率
中条件概率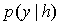 最大的标注序列:
最大的标注序列:
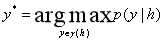 (3-5)
(3-5)
3.2.3 问答系统实体抽取方法实现及结果分析
本文针对智能家居问答系统设计问答系统实体抽取实现方法,基于词法分析、CRF条件随机场、数据标注实现对实体的抽取;并针对智能家居语料库,对实体抽取效果进行对比分析。问答系统实体抽取算法实现流程如图3-2所示。
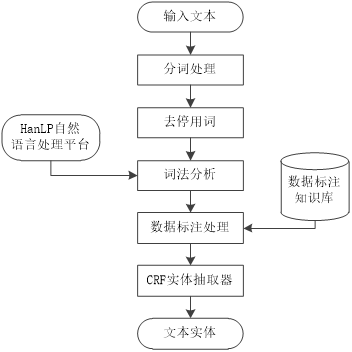
图3-2 实体抽取实现流程
Fig3-2 Entity extraction implementation process
(1)实体抽取算法实现
文本预处理:智能家居问答系统对输入文本进行预处理,实现分词、去停用词,完成文本特征的提取。将问句的长文本序列切分为以词语为单元的词语文本序列。以“请问今天的温度是多少?”为例,其分词结果为“请问 / 今天 / 的 / 温度 / 是 / 多少 / ?”;然后将词语序列中的无关词汇剔除,如“的”,得到“请问 / 今天 / 温度 / 是 / 多少 / ?”;再者,对词语进行核心词汇提取,获取序列中的实体“今天 / 温度 / 是 / 多少 / ?”;

图3-3 文本预处理
Fig3-3 Text Preprocessing
词法分析:本文采用HanLP自然语言分析平台对文本进行词法分析处理。
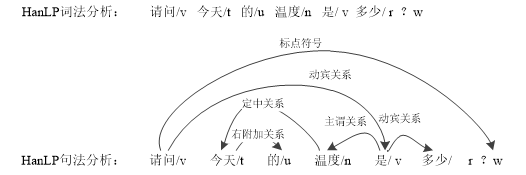
图3-4 HanLP词法句法分析
Fig 3-4 HanLP Lexical Syntax Analysis
CRF实体抽取:输入文本经过文本预处理完成分词、去停用词后获得文本的基本特征,然后调用HanLP自然语言处理平台获取文本的词法、句法特性,再根据数据标注知识库对文本进行标记,从而构成CRF实体抽取训练数据集。
针对智能家居问答系统应用场景,本文在MUC命名实体标注规则的基础上增加物品类型(Goods,GOODS),指令类型(Order,ORDER)两类,用来标记智能家居相关实体。
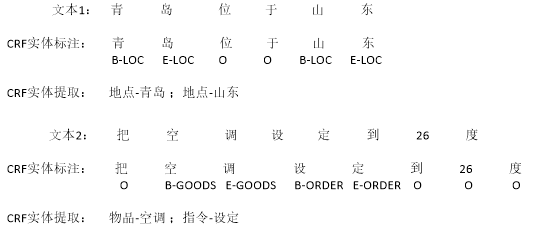
图3-5 CRF实体抽取
Fig3-5 CRF entity extraction
(2)实验结果分析
1)基于规则的实体抽取结果分析
本文针对智能家居知识图谱构建智能家居文本集,包括家居类操作文本知识431条,其中家居电器名词57个,动作指令词语98个,时间词语112个,数量词131个。通过对以上词汇编写抽取规则触发词表,调用规则抽取算法,最后完成对家居类实体的抽取。其中,识别出的电器名词为52个,正确识别电器名词48个;识别出的动作指令词为91个,正确识别的动作指令词87个;识别出的时间词为105个,正确识别的时间词语97个;识别出的数量词为125个,正确识别的数量词114个,得到较好的准确率、召回率和F值,实验结果如表3-2所示。
表3-2 规则抽取实验结果
Table3-2 Rule extraction experiment results
|
精确率P |
召回率R |
F值 |
电器名词 |
92.31% |
84.21% |
87.77% |
动作词 |
95.60% |
88.78% |
92.07% |
时间词 |
92.38% |
86.61% |
89.40% |
数量词 |
91.20% |
87.02% |
89.06% |
2)基于CRF的实体抽取结果分析
本文针对智能家居知识图谱构建互联网数据文本集,包括百科类文本知识500条,根据MUC命名实体规则,标注人名100个,机构名100个。训练CRF抽取模型,完成互联网实体的抽取。其中,识别出的人名为91个,正确识别人名85个;识别出的机构名为89个,正确识别的机构名83个。将CRF模型分别同HMM模型,最大熵模型进行比较,得到CRF模型具有较好的精确率P、召回率R和F值,实验结果如表3-3所示。
表3-3 抽取实验结果
Table3-3 Extraction experiment results
|
|
精确率P |
召回率R |
F值 |
隐马尔可夫 模型 |
人名 |
91.25% |
73% |
81.11% |
机构名 |
88.89% |
72% |
79.56% |
最大熵模型 |
人名 |
92.94% |
79% |
85.40% |
机构名 |
93.02% |
80% |
86.02% |
条件随机场 模型 |
人名 |
93.41% |
85% |
89.0% |
机构名 |
93.26% |
83% |
87.83% |
3.3 智能家居问答系统关系抽取
本文将实体关系抽取出来表达成三元组,完成知识的最终表示。本节通过阐述不同关系抽取方法,总结现有抽取方法的优势与不足,基于SVM构建关系抽取分类器实现问答系统的实体关系抽取。
3.3.1 关系抽取方法
关系抽取是知识图谱的研究重点方向。基于机器学习的关系抽取算法有:有监督、无监督、弱监督关系抽取等[19]。
1、有监督关系抽取
有监督关系抽取是利用关系分类器完成对关系的分类抽取,有基于特征向量提取和基于核函数提取两种。
基于核函数的关系抽取方法能避免构造特征向量准确性不高的问题[20]。因此,对实体关系的表示比较灵活。因此本文选用基于核函数的SVM算法进行关系抽取。
2、无监督关系抽取
无监督关系抽取采用实体所处上下文来表示语义关系特征。通过釆集到上下文来表达语义关系特征,引入层次聚类将较高特征相似度的实体对归为一簇,并将聚类簇的词语定义为关系名称[63]。无监督关系抽取能够有效的发现新关系,但是发现的新关系只是相似模板的聚类,因此,实现规则化较为困难。
3、弱监督关系抽取
弱监督关系抽取包括:半监督学习提高抽取的准确度;通过已有知识库中的三元组自动回标含有三元组内实体的文本作为训练数据[63]。
3.3.2 SVM关系抽取分类器方法
本文选用基于SVM实体关系抽取方法。该方法是将实体的不同关系类型当作一种基于特征的标签,从而将实体关系抽取转化为给定文本以及其特征的分类问题[59]。针对SVM的不同核函数,提出一种基于核函数的SVM关系抽取分类器。
支持向量机算法实现:
(1)线性支持向量机
线性分类器是指在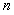 维数据空间中定义一个超平面。在此,定义
维数据空间中定义一个超平面。在此,定义
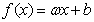 (3-6)
(3-6)
即,当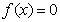 时,超平面
时,超平面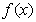 将数据空间分为两类,其中,
将数据空间分为两类,其中,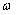 、
、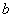 为维向量。因此,如果数据空间都线性可分,那么则存在最优分类平面使得
为维向量。因此,如果数据空间都线性可分,那么则存在最优分类平面使得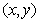 到的距离
到的距离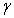 最短。
最短。
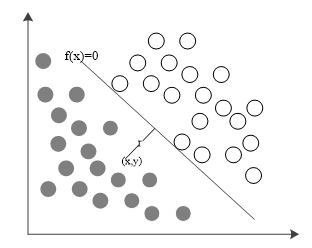
图3-6 最优分类平面
Fig3-6 Optimal classification plane
对于维向量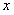 有:
有:
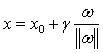 (3-7)
(3-7)
且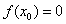 ,则有
,则有
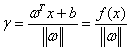 (3-8)
(3-8)
函数间距和几何间距为:
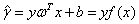 (3-9)
(3-9)
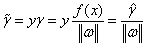 (3-10)
(3-10)
在此,令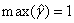 ,则
,则
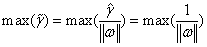 (3-11)
(3-11)
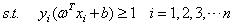
有,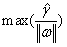 等价于
等价于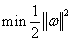 ,则:
,则:
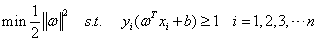 (3-12)
(3-12)
因此,当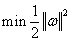 取最小值时,即可实现二次优化。由拉格朗日对偶变换引入拉格朗日对偶变量
取最小值时,即可实现二次优化。由拉格朗日对偶变换引入拉格朗日对偶变量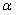 ,有:
,有:
 (3-13)
(3-13)
令
满足Karush-Kuhn-Tucker条件,得:
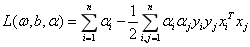 (3-14)
(3-14)
对对偶变量求极大,有
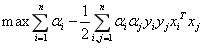 (3-15)
(3-15)
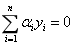 (3-16)
(3-16)
得:
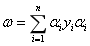 (3-17)
(3-17)
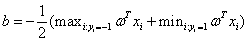 (3-18)
(3-18)
其中,为最优分类平面的法向量,为截距。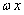 是维向量与维向量的内积。
是维向量与维向量的内积。
(2)非线性支持向量机
如果数据集为线性数据,可以采用线性分类器对数据进行分类处理[37]。当数据为非线性数据时,引入核函数,常用核函数有:
多项式核函数:
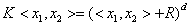 (3-19)
(3-19)
空间维度: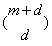 ,
,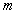 是原始空间维度;
是原始空间维度;
高斯核函数:
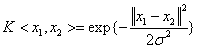 (3-20)
(3-20)
线性核函数:
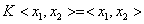 (3-21)
(3-21)
在此,引入松弛变量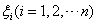 ,则约束条件变为:
,则约束条件变为:
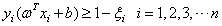 (3-22)
(3-22)
最新优化目标为:
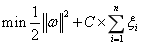 (3-23)
(3-23)
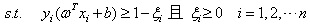
C为惩罚系数。
采用拉格朗日乘法求解,有:
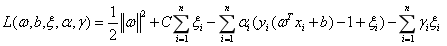 (3-24)
(3-24)
推理得:
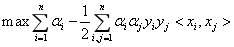 (3-25)
(3-25)
其中,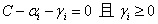
最终得到:
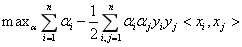 (3-26)
(3-26)
3.3.3 问答系统关系抽取方法实现及结果分析
本文针对智能家居问答系统设计实现问答系统知识图谱关系抽取实现方法,基于文本预处理、特征提取、SVM关系抽取实现对关系的抽取。问答系统关系抽取实现流程如图所示。
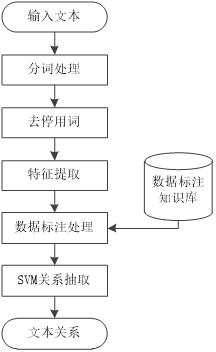
图3-7 关系抽取实现流程图
Fig3-7 Relationship Extraction Implementation Flowchart
(1)关系抽取算法实现
文本预处理:如前文所述,本文采用结巴分词技术对输入文本进行分词处理,并导入停用词表过滤停用词。将问句的长文本序列切分为以词语为单元的词语文本序列。获取其分词结果,然后将词语序列中的无关词汇剔除,再对词语进行核心词汇提取,获取序列中的实体。
特征提取:在自然语言处理中,把文本数据变成向量数据,在向量数据中可以得到文本数据当中的语言特性,这种方式叫做文本特征提取。
本文运用TF-IDF (Term Frequency - Inverse Document Frequency),即“词频-逆文本频率”进行文本特征提取。
TF-IDF计算公式:
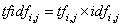 (3-31)
(3-31)
其中,
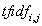 是指词语
是指词语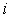 相对于文本
相对于文本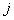 的特征表示;
的特征表示;
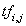 是词语出现次数的占比;
是词语出现次数的占比;
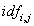 是文本中所有词语出现的次数之和。
是文本中所有词语出现的次数之和。
SVM关系抽取:针对智能家居问答系统知识图谱应用场景,构建基于核函数的SVM关系抽取分类器。根据分类器的分类结果确定该文本的对应关系类型。
(2)实验结果分析
本文针对智能家居知识图谱构建互联网数据文本测试集,包括百科类文本知识200条,经过对知识数据进行标注得到关系类型3类。在此,分别针对线性核函数、高斯核函数、多项式核函数分别构建SVM关系抽取分类器。其中,高斯核函数抽取结果最佳,抽取出的关系数为178个,正确关系数163个,实验结果如表3-4所示。
表3-4 关系抽取实验结果
Table3-4 Relationship Extraction experiment results
SVM核函数 |
精确率P |
召回率R |
F值 |
线性核函数 |
83.78% |
77.5% |
80.52% |
多项式核函数 |
85.41% |
79% |
82.08% |
高斯核函数 |
88.11%% |
81.5% |
84.68% |
3.4 小结
本章介绍智能家居问答知识图谱的构建方法。分别从知识图谱构建概述、智能家居问答系统实体抽取、智能家居问答系统关系抽取三方面进行阐述。其中,智能家居问答系统实体抽取从实体抽取方法概述、CRF实体抽取、问答系统实体抽取方法实现三方面介绍实体抽取的实现算法;关系抽取主要从关系抽取方法、SVM分类器、问答系统方法实现三方面阐述关系抽取实现算法。


